



Ordering, Transactions and Exactly-Once Semantics in Data Integrations
There are three important aspects of robust data integrations when using queues: global ordering of messages, multi-message transactionality, and exactly-once semantics.

This post is fifth part in a series about building and adopting a modern streaming data integration platform. Here we discuss the architectural patterns related to data integrations.
There are several architectural patterns when working with data integrations, with various benefits and drawbacks. In this post I will discuss some that are most relevant when you are working with near real-time data integrations.
This post is about the core architectural patterns, rather than comprehensive “reference architectures”. Support functions, such as monitoring, data quality, reconcilation, monitoring, governance etc. are not included in the diagrams.
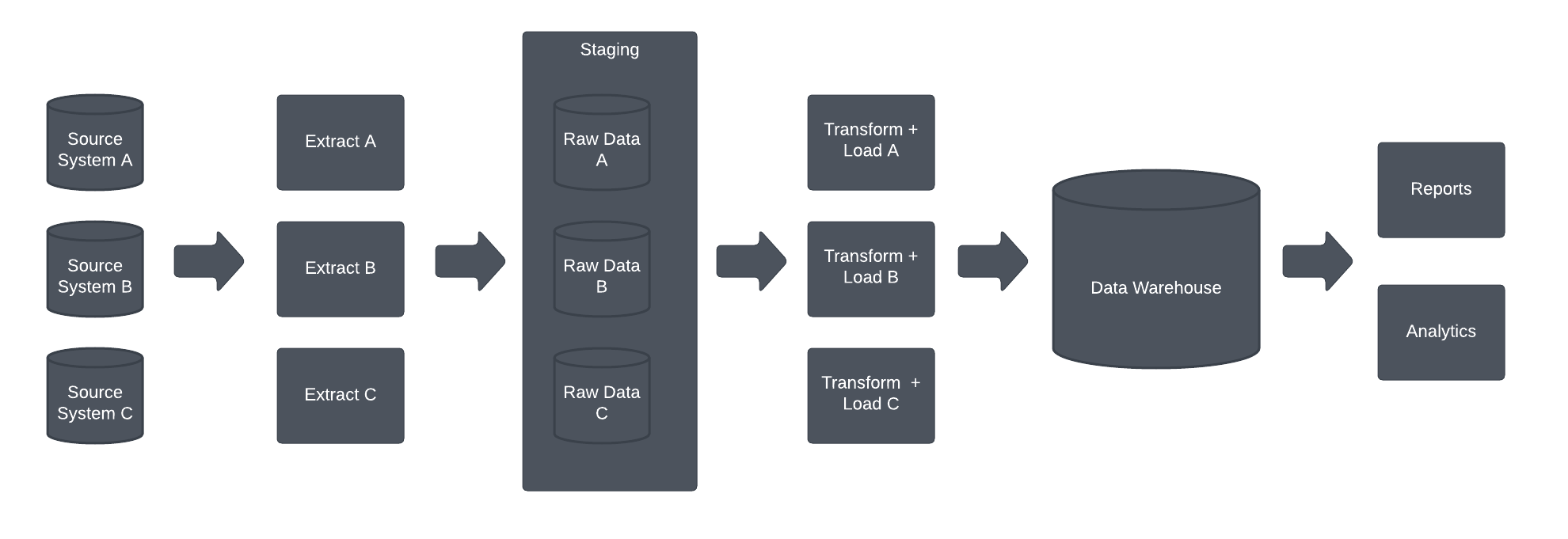
The traditional data integration is based on ETL batch processing. Data is extracted from source systems, and collected into a staging area. The data is transformed and loaded into a data warehouse. The data warehouse is used for reporting, often through data marts.
The benefits of this architecture are the relative simplicity, tool support and performance. The downside is data freshness due to batch processing, which makes it unsuitable for operative applications (OLTP loads).
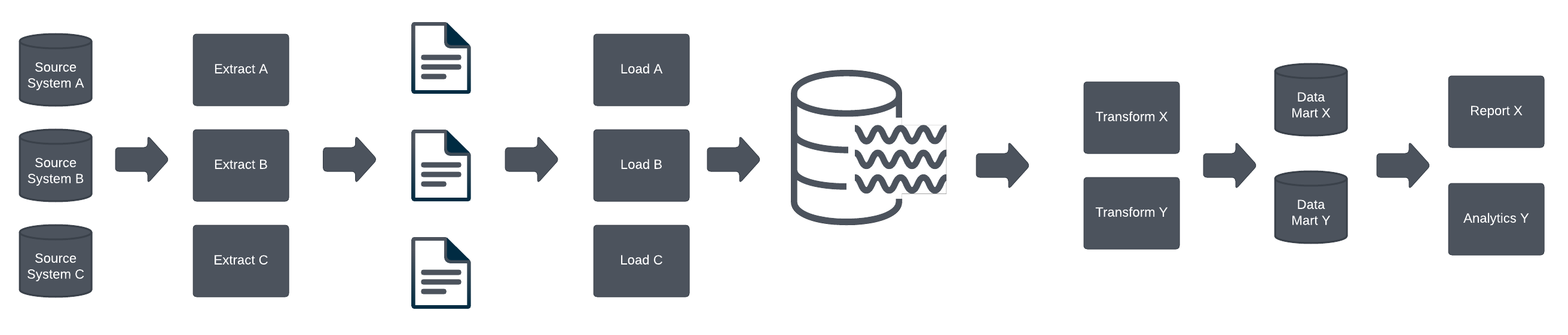
More recently, data integrations are being built with big data integration architecture. They are running on the cloud and based on ELT batch processing. All data is extracted from source systems, and stored in some raw data repository, such as AWS S3 storage buckets. The raw data files are then loaded into the data lake. Snowflake is typically used for the storage. Data marts are often created for data usage.
One benefit of such architecture is that typically all data from source system is in the data lake, so you don’t need to change source integration if you need to access more data. Performance compared to ETL batch processing may be another benefit.
Such architectures also have limitations for operative applications. The technology is not optimized for OLTP loads, and licensing costs may also limit the usefulfulness of this architecture for operative applications.
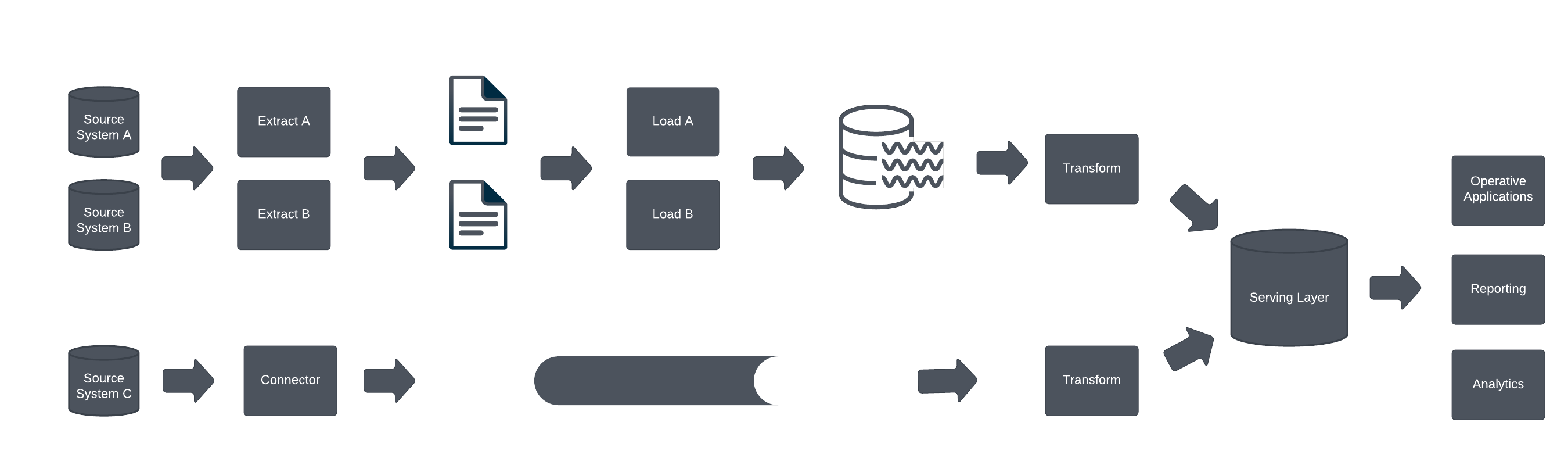
Lambda architecture allows co-existence of the batch-oriented data integrations and near real-time data integrations. These diffrent mechanisms are integrated into a coherent whole.
The benefit of Lambda architecture is that it is possible to evolve existing batch processing towards real-time data streaming. OLTP and OLAP loads can coexist. There is no need to rebuild existing source integrations.
The drawback of Lambda architecture is that it may be complex. Depending on how the integrations are built, the work related to integrations might need to duplicated.
More difficult issue to solve is data integrity. As there is no central pipeline that all data goes through. If there are relationships between systems, different “clock speeds” of batch and near real-time integrations mean that enforcing data integrity is very complex.
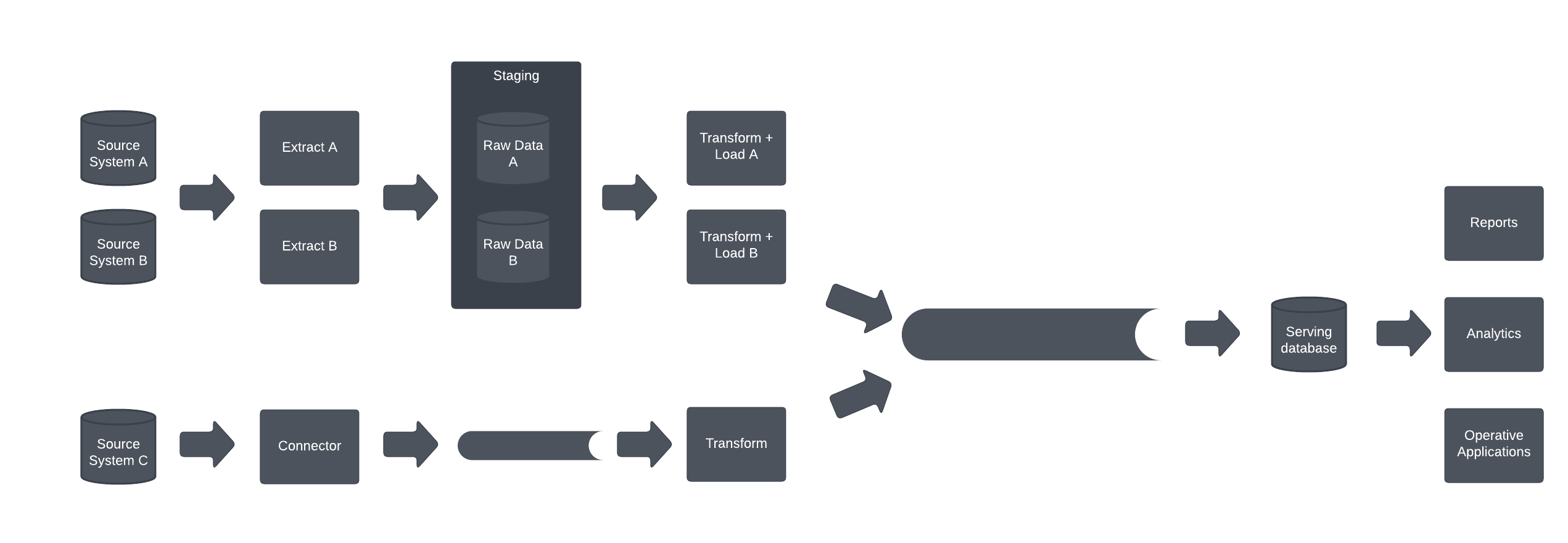
Kappa architecture is an evolution over Lambda architecture. It is often possible to stream all the batch data through real-time data streams as well. This simplifies the architecture. Since there is single control point – and indeed central log that serializes the events, enforcing data integrity becomes possible – while there are still some limitations.
Many corporate environments have “wide data”, in other words number of entity types is relatively large, but number of entities for each entity type is relatively small – number of entities of each entity type are in the millions rather than in the billions. In any case, the performance of the data streams and the central control point becomes very important.
If you need consulting related to system architectures in general, or data integrations in particular, please do not hesitate to contact Mikko Ahonen through the contact page.
There are three important aspects of robust data integrations when using queues: global ordering of messages, multi-message transactionality, and exactly-once semantics.
Data integrity is especially important in data integrations, whether you use batch or stream processing to deliver data. There are multiple communication patterns available, and only some of them are useful for real-time integrations. All of them have some caveats regarding data integrity.
It seems we have lost our integrity on data integrity. We build systems mostly with eventual consistency as the default approach. At best, eventual consistency pushes the data integrity issues to application developers. At worst, data integrity is just ignored and resolved when problems arise. Better approaches have been available at least from the 1970s, but they seem to be ignored in modern software development.




{kind=link}